# 加载必要的依赖库
import re # for regular expressions
import pandas as pd
pd.set_option("display.max_colwidth", 200)
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import string
import nltk # for text manipulation
import warnings
warnings.filterwarnings("ignore", category=DeprecationWarning) # 不显示警告
# 1.读取数据。读取训练数据和测试数据
train = pd.read_csv("train.csv")
test = pd.read_csv("test.csv")
# 2.数据概览。查看并展示数据集中的指定数据信息。
train.head() # 查看训练数据的前五行
可以看到,数据包含三列,id,label和tweet。label是一个二进制数值,tweet包含了我们需要文本的内容。 看了头部数据之后,我们大概可以开始清理数据了,清理大概可以从下面几个方面入手:
由于隐私保护的问题,Twitter的用户名已经被隐去,取而代之的是‘@user’。 这个标签没有任何实际意义。
我们也考虑去掉标点符号,数字甚至特殊字符,他们对数据分析起不到任何作用。
大多数太短的词起不到什么作用,比如‘pdx’,‘his’,‘all’。所以我们也把这些词去掉。
在第四个数据中,有一个单词‘love’.与此同时,在余下的语料中我们可能会有更多的单词,例如loves,loving,lovable等等。这些词其实都是一个词。如果我们能把这些词都归到它们的根源上,也就是都转换成love,那么我们就可以大大降低不同单词的数量,而不会损失太多信息。
可以看到,数据包含三列,id,label和tweet。label是一个二进制数值,tweet包含了我们需要文本的内容。 看了头部数据之后,我们大概可以开始清理数据了,清理大概可以从下面几个方面入手:
- 由于隐私保护的问题,Twitter的用户名已经被隐去,取而代之的是‘@user’。 这个标签没有任何实际意义。
- 我们也考虑去掉标点符号,数字甚至特殊字符,他们对数据分析起不到任何作用。
- 大多数太短的词起不到什么作用,比如‘pdx’,‘his’,‘all’。所以我们也把这些词去掉。
- 在第四个数据中,有一个单词‘love’.与此同时,在余下的语料中我们可能会有更多的单词,例如loves,loving,lovable等等。这些词其实都是一个词。如果我们能把这些词都归到它们的根源上,也就是都转换成love,那么我们就可以大大降低不同单词的数量,而不会损失太多信息。
(1)去除‘@user’等无效字符
如上所述,这些文本内容包含很多Twitter标记,这些都是Twitter上面的用户信息。我们需要把这些内容删掉,他们对于数据分析没有什么帮助。 方便起见,先把训练集和测试集合起来,避免在训练集和测试集上重复操作的麻烦。
combi = train._append(test, ignore_index=True) # 将训练集和测试集合并
下面是一个自定义的方法,用于正则匹配删除文本中不想要的内容。它需要两个参数,一个是原始文本,一个是正则规则。这个方法的返回值是原始字符串清除匹配内容后剩下的字符。
def remove_pattern(input_txt, pattern):
r = re.findall(pattern, input_txt)
for i in r:
input_txt = re.sub(i, ”, input_txt)return input_txt
现在,我们新建一列tidy_tweet ,用于存放处理后的内容,就是上面说的去掉Twitter标记的内容,并查看。
combi[“tidy_tweet”] = np.vectorize(remove_pattern)(combi[“tweet”], “@[\w]*”)
combi.head() # 查看combi的前五行数据
(2)去除标点符号、数字和特殊字符
这些字符都是没有意义的。跟上面的操作一样,我们把这些字符也都剔除掉。 使用替换方法,去掉这些非字母内容
combi[“tidy_tweet”] = combi[“tidy_tweet”].str.replace(“[^a-zA-Z#]”, ” “)
combi.head(5) # 使用head()方法查看前五行数据
(3)移除短单词
这里要注意到底多长的单词应该移除掉。我们选择小于等于三的都去掉。例如hmm,oh这样的都没啥用,删掉这些内容好一些。
combi[“tidy_tweet”] = combi[“tidy_tweet”].apply(lambda x: ” “.join([w for w in x.split() if len(w)>3]))
combi.head() # 查看前五行数据
4)符号化
下面我们要把清洗后的数据集符号化。符号指的是一个个的单词,符号化的过程就是把字符串切分成符号的过程。
tokenized_tweet = combi[‘tidy_tweet’].apply(lambda x: x.split()) # tokenizing
tokenized_tweet.head() # 查看前五行数据
(5)提取词干
提取词干说的是基于规则从单词中去除后缀的过程。例如,play,player,played,plays,playing都是play的变种。
from nltk.stem.porter import *
stemmer = PorterStemmer()tokenized_tweet = tokenized_tweet.apply(lambda x: [stemmer.stem(i) for i in x]) # stemming
tokenized_tweet.head() # 查看前五行数据
现在,我们把这些符号重新拼回去。
for i in range(len(tokenized_tweet)):
tokenized_tweet[i] = ” “.join(tokenized_tweet[i])combi[“tidy_tweet”] = tokenized_tweet
combi.head() # 查看前五行数据
以上,我们的数据便处理结束了,tidy_tweet便是我们要提取特征的文本,label则是我们的标签。
2.从清洗后的推文中提取特征
要分析清洗后的数据,就要把它们转换成特征。根据用途来说,文本特征可以使用很多种算法来转换。比如词袋模型(Bag-Of-Words),TF-IDF,word Embeddings之类的方法。 在本文中,我们TF-IDF这个方法。
TF-IDF是基于词频的。它跟词袋模型的区别在于,主要是它还考虑了一个单词在整个语料库上的情况而不是单一文章里的情况。 TF-IDF方法会降低常用单词的权重,同时对于某些在整个数据集上出现较少,但是在部分文章中表现较好的词给予了较高的权重。 让我们来深入了解一下TF-IDF:
- TF = 单词t在一个文档中出现的次数 / 文档中全部单词的数目
- IDF = log(N/n),N是全部文档数目,n是单词t出现的文档数目
- TF-IDF = TF*IDF
下面我们来进行TF-IDF特征提取:
from sklearn.feature_extraction.text import TfidfVectorizer
tfidf_vectorizer = TfidfVectorizer(max_df=0.90, min_df=2, max_features=1000, stop_words=”english”)
# TF-IDF feature matrix
tfidf = tfidf_vectorizer.fit_transform(combi[“tidy_tweet”])
3.使用特征进行数据分析模型训练
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import f1_score# 选择特征输入
train_tfidf = tfidf[:31962,:]
test_tfidf = tfidf[31962:,:]# 对数据进行划分
xtrain_tfidf, xvalid_tfidf, ytrain, yvalid = train_test_split(train_tfidf, train[‘label’],
random_state=42,
test_size=0.3)
# 调用逻辑回归函数进行训练
lreg = LogisticRegression()
lreg.fit(xtrain_tfidf, ytrain) # training the model
输出:LogisticRegression()
4.数据分析模型预测
from sklearn.metrics import roc_auc_score
from sklearn.metrics import classification_report#对于测试集x_test进行预测
prediction = lreg.predict_proba(xvalid_tfidf)
prediction_int = prediction[:,1] >= 0.25
prediction_int = prediction_int.astype(np.int_)# 其他指标计算
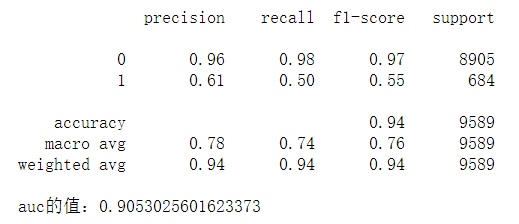
print(classification_report(yvalid, prediction_int))# auc计算
auc=roc_auc_score(yvalid, prediction[:,1])
print(“auc的值:{}”.format(auc))
125jz网原创文章。发布者:江山如画,转载请注明出处:http://www.125jz.com/12309.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫