AdaGrad算法特点:
如果目标函数有关自变量中某个元素的偏导数一直都较大,那么该元素的学习率将下降较快;反之,如果目标函数有关自变量中某个元素的偏导数一直都较小,那么该元素的学习率将下降较慢。
自变量中每个元素的学习率在迭代过程中一直在降低(或不变)。
所以,当学习率在迭代早期降得较快且当前解依然不佳时,AdaGrad算法在迭代后期由于学习率过小,可能较难找到一个有用的解。
Pytorch简洁实现AdaGrad算法–使用optim.Adagrad
通过名称为Adagrad的优化器方法,我们便可使用PyTorch提供的AdaGrad算法来训练模型。
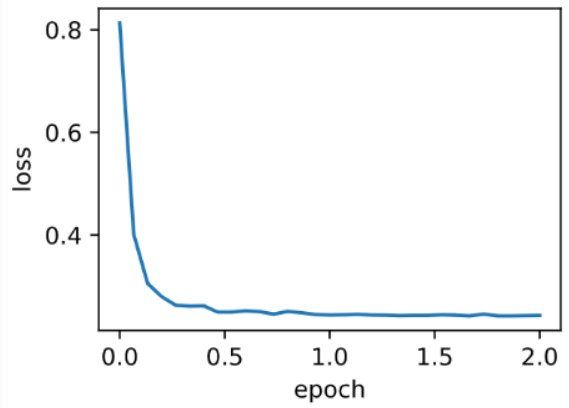
d2l.train_pytorch_ch7(torch.optim.Adagrad, {‘lr’: 0.1}, features, labels)
输出:
loss: 0.243147, 0.040675 sec per epoch
总结
- AdaGrad算法在迭代过程中不断调整学习率,并让目标函数自变量中每个元素都分别拥有自己的学习率。
- 使用AdaGrad算法时,自变量中每个元素的学习率在迭代过程中一直在降低(或不变)。
125jz网原创文章。发布者:江山如画,转载请注明出处:http://www.125jz.com/12302.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫