Batch Normalization, 批标准化, 和普通的数据标准化类似, 是将分散的数据统一的一种做法。
训练更深层的神经网络一直是深度学习中提高模型性能的重要手段之一。
批规范化操作,不仅加快了模型收敛速度,而且更重要的是在一定程度缓解了深层网络的一个难题“梯度弥散”,从而使得训练深层网络模型更加容易和稳定。另外,批规范化操作不光适用于深层网络,对传统的较浅层网络而言,批规范化也能对网络泛化性能起到一定提升作用。目前批规范化已经成为了几乎所有卷积神经网络的标配。
首先,我们来看一下批规范化操作(简称 BN)的流程。顾名思义,“批规范化”,即在模型每次随机梯度下降训练时,通过mini-batch来对相应的网络响应做规范化操作,使得结果(输出信号各个维度)的均值为0,方差为1。
BN 算法


我们引入一些 batch normalization 的公式. 这三步就是我们在刚刚一直说的 normalization 工序, 但是公式的后面还有一个反向操作, 将 normalize 后的数据再扩展和平移. 原来这是为了让神经网络自己去学着使用和修改这个扩展参数 gamma, 和 平移参数 β, 这样神经网络就能自己慢慢琢磨出前面的 normalization 操作到底有没有起到优化的作用, 如果没有起到作用, 我就使用 gamma 和 belt 来抵消一些 normalization 的操作.
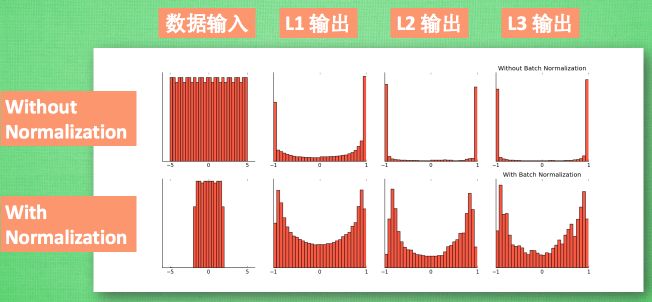
最后我们来看看一张神经网络训练到最后, 代表了每层输出值的结果的分布图. 这样我们就能一眼看出 Batch normalization 的功效啦. 让每一层的值在有效的范围内传递下去。
BN 来规范化某些层或所有层的输入,从而可以固定每层输入信号的均值与方差。这样一来,即使网络模型较深层的响应或梯度很小,也可通过BN的规范化作用将其的尺度变大,以此便可解决深层网络训练很可能带来的“梯度弥散”问题。
在实验中, 研究人员发现可通过BN来规范化某些层或所有层的输入,从而可以固定每层输入信号的均值与方
差。这样一来,即使网络模型较深层的响应或梯度很小,也可通过BN的规范化作用将其的尺度变大,以此便可解决深层网络训练很可能带来的“梯度弥散”问题。
一个直观的例子:对一组很小的随机数做ℓ2 规范化操作:

关于BN 的使用位置,在卷积神经网络中BN 一般应作用在非线性映射函数前。另外,若神经网络训练时遇到收敛速度较慢,或“梯度爆炸”等无法训练的状况发生时也可以尝试用BN来解决。同时,常规使用情况下同样可加入BN 来加快模型的训练速度,甚至提高模型精度。
相关概念
归一化:
1)把数据变成(0,1)或者(1,1)之间的小数。主要是为了数据处理方便提出来的,把数据映射到0~1范围之内处理,更加便捷快速。
2)把有量纲表达式变成无量纲表达式,便于不同单位或量级的指标能够进行比较和加权。归一化是一种简化计算的方式,即将有量纲的表达式,经过变换,化为无量纲的表达式,成为纯量。
标准化:
在机器学习中,我们可能要处理不同种类的资料,例如,音讯和图片上的像素值,这些资料可能是高维度的,资料标准化后会使每个特征中的数值平均变为0(将每个特征的值都减掉原始资料中该特征的平均)、标准差变为1,这个方法被广泛的使用在许多机器学习算法中(例如:支持向量机、逻辑回归和类神经网络)。
中心化:平均值为0,对标准差无要求
归一化和标准化的区别:
归一化是将样本的特征值转换到同一量纲下把数据映射到[0,1]或者[-1, 1]区间内,仅由变量的极值决定,因区间放缩法是归一化的一种。标准化是依照特征矩阵的列处理数据,其通过求z-score的方法,转换为标准正态分布,和整体样本分布相关,每个样本点都能对标准化产生影响。它们的相同点在于都能取消由于量纲不同引起的误差;都是一种线性变换,都是对向量X按照比例压缩再进行平移。
标准化和中心化的区别:
标准化是原始分数减去平均数然后除以标准差,中心化是原始分数减去平均数。 所以一般流程为先中心化再标准化。
无量纲:我的理解就是通过某种方法能去掉实际过程中的单位,从而简化计算。
125jz网原创文章。发布者:江山如画,转载请注明出处:http://www.125jz.com/11121.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫