深度学习中最重要的超参数:学习率
什么是学习率
学习率就是SGD算法中的ϵk[^23]:


学习率决定了在每步参数更新中,模型参数有多大程度(或多快、多大步长)的调整[^24]。在之前,学习率是一个固定的数ϵ,这时候学习率是超参数。后来实践中发现,逐渐减少学习率是必要的[^26],也就是学习率schedule ϵ1,…,ϵk,这时候,学习率在一定程度上是训练参数。
学习率的影响(重要性)
学习率需要在收敛和过火之间权衡[^25]。
学习率太小,则收敛得慢。学习率太大,则损失会震荡甚至变大。
如果使用的学习率太大,会导致网络无法收敛。
不同学习率的影响如下[^2]:
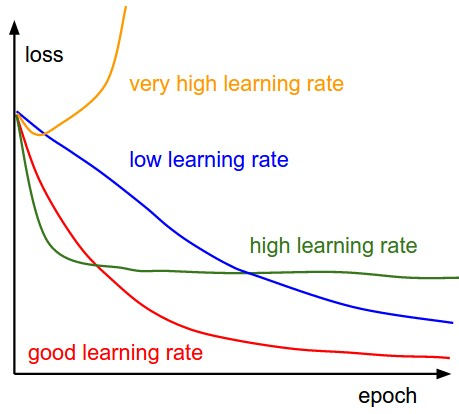
学习率可能是最重要的参数了。如果你只有时间调整一个参数,那么就是学习率[^17]。
学习率还会跟优化过程的其他方面相互作用,这个相互作用可能是非线性的。小的batch size最好搭配小的学习率,因为batch size越小也可能有噪音,这时候就需要小心翼翼地调整参数[^18]。
轻量级目标检测SSD(single shot multibox detector )算法
SSD 算法的名字非常的直观,指出了 SSD 算法是多框预测的一步目标检测算法。SSD 算法在目标检测过程中直接使用卷积神经网络来进行目标物体的检测工作。
SSD 算法的特点在于:
(1)SSD 算法在检测不同大小的物体时使用的是不同尺度的特征图,物体的大小和检测时使用的特征图大小成反比。
(2)SSD 算法使用的 priors anchor 大小并不固定。根据目标检测工作的需求,SSD 算法可以调整先验框的尺度和长宽比。
SSD 算法之所以能成为目标检测算法中的代表性算法,是因为 SSD 在算法的设计上有许多出彩的地方。
(1)SSD 算法在检测不同大小的物体时使用的是不同尺度的特征图,这使得 SSD 算法可以兼顾大目标和小目标的检测工作,适用于几乎所有的物体来进行目标检测,所以SSD 算法的 mAP 高达 70%以上。
(2)SSD 算法可以根据目标检测工作的需求来调整默认窗口的长宽比。默认窗口的设置就是为了让 SSD 算法能够完成对滑动框的分类和回归。设置了默认窗口就是设置了有效感受野的大小。一般来说,理论感受野的面积大于有效感受野面积的大小,而有效感受野面积的大小则大于先验框面积的大小。SSD 算法需要根据有效感受野来确定标签位置以完成目标检测中的分类工作。标签的位置则需要通过默认窗口和标注数据进行匹配来确定。默认窗口和标注数据能够匹配就是正样本,默认窗口和标注数据不能匹配就是负样本。
(3)SSD 算法设置可以改变长宽比大小的默认窗口就是为了更好的完成默认窗口和标注数据的匹配工作。SSD 算法对输入的数据进行了增强操作。因为 SSD 算法可以同时兼顾大目标和小目标的检测工作,所以 SSD 算法对输入的数据进行了简单的放大和缩小操作。SSD 算法的放大操作就是将输入的数据放大到两倍在截取原图一样大小的图片数据后进行大目标的检测,SSD 算法的缩小操作并没有真的缩小输入的原始数据,而是在不改变原始数据的情况下制作一个原始数据 16 倍大的背景图,再讲原始数据图放入背景图中进行小目标的检测。
SSD 算法虽然有众多优点,但还有可以改进的地方。虽然 SSD 算法可以同时兼顾大目标和小目标的检测工作,但是比起其他目标检测算法 SSD 算法在小目标的检测上并没有什么优势。自 SSD 算法提出以来,涌现了许多研究和改进 SSD 算法的论文为改变 SSD 算法在小目标检测上的颓势提供了新的思路。无论是调整小目标检测的特征图还是修改输入数据的尺寸都能有效的解决这个问题。SSD 算法的先验框也有一定的缺陷,容易产生偏移不能准确的定位目标物体。总之,SSD 算法的优化改进工作还是任重而道远的。
sigmoid函数
Sigmoid函数,即
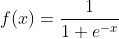
。是神经元的非线性作用函数。广泛应用在神经网络中。
sigmoid函数也叫Logistic函数,用于隐层神经元输出,取值范围为(0,1),它可以将一个实数映射到(0,1)的区间,可以用来做二分类。在特征相差比较复杂或是相差不是特别大时效果比较好。Sigmoid作为激活函数有以下优缺点:
优点:平滑、易于求导。
缺点:激活函数计算量大,反向传播求误差梯度时,求导涉及除法;反向传播时,很容易就会出现梯度消失的情况,从而无法完成深层网络的训练。
Sigmoid函数由下列公式定义

其对x的导数可以用自身表示:

125jz网原创文章。发布者:江山如画,转载请注明出处:http://www.125jz.com/11106.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫
评论列表(3条)
CAN总线协议(Controller Area Network),控制器局域网总线,是德国BOSCH(博世)公司研发的一种串行通讯协议总线,它可以使用双绞线来传输信号,是世界上应用最广泛的现场总线之一。
CAN总线用单根信号线就可以通信,但还是配备了第二根导线,第二根导线与第一根导线信号为差分关系,可以有效抑制电磁干扰; 直接通信距离最远可达10KM(速率4Kbps以下)
PyTorch是一个开源的Python机器学习库,基于Torch,用于自然语言处理等应用程序。
2017年1月,由Facebook人工智能研究院(FAIR)基于Torch推出了PyTorch。它是一个基于Python的可续计算包,提供两个高级功能:1、具有强大的GPU加速的张量计算(如NumPy)。2、包含自动求导系统的深度神经网络。
2022年9月,扎克伯格亲自宣布,PyTorch 基金会已新鲜成立,并归入 Linux 基金会旗下。
PyTorch的前身是Torch,其底层和Torch框架一样,但是使用Python重新写了很多内容,不仅更加灵活,支持动态图,而且提供了Python接口。它是由Torch7团队开发,是一个以Python优先的深度学习框架,不仅能够实现强大的GPU加速,同时还支持动态神经网络。
PyTorch既可以看作加入了GPU支持的numpy,同时也可以看成一个拥有自动求导功能的强大的深度神经网络。除了Facebook外,它已经被Twitter、CMU和Salesforce等机构采用。
优点:
PyTorch是相当简洁且高效快速的框架
设计追求最少的封装
设计符合人类思维,它让用户尽可能地专注于实现自己的想法
与google的Tensorflow类似,FAIR的支持足以确保PyTorch获得持续的开发更新
PyTorch作者亲自维护的论坛 供用户交流和求教问题
入门简单
基础环境:
一台PC设备、一张高性能NVIDIA显卡(可选)、Ubuntu系统。
R-CNN的全称是Region-CNN,是第一个成功将深度学习应用到目标检测上的算法。R-CNN基于卷积神经网络(CNN),线性回归,和支持向量机(SVM)等算法,实现目标检测技术。
传统的目标检测方法大多以图像识别为基础。 一般可以在图片上使用穷举法选出所有物体可能出现的区域框,对这些区域框提取特征并使用图像识别方法分类, 得到所有分类成功的区域后,通过非极大值抑制(Non-maximumsuppression)输出结果。
R-CNN遵循传统目标检测的思路,同样采用提取框,对每个框提取特征、图像分类、 非极大值抑制四个步骤进行目标检测。只不过在提取特征这一步,将传统的特征(如 SIFT、HOG 特征等)换成了深度卷积网络提取的特征。R-CNN 体框架如图1所示。
对于一张图片,R-CNN基于selective search方法大约生成2000个候选区域,然后每个候选区域被resize成固定大小,并送入一个CNN模型中,最后得到一个特征向量。然后这个特征向量被送入一个多类别SVM分类器中,预测出候选区域中所含物体的属于每个类的概率值。每个类别训练一个SVM分类器,从特征向量中推断其属于该类别的概率大小。为了提升定位准确性,R-CNN最后又训练了一个边界框回归模型,通过边框回归模型对框的准确位置进行修正。